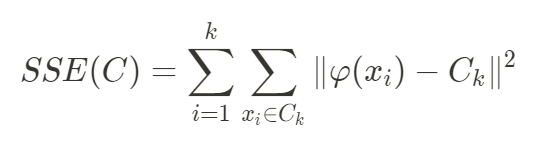We know that k-means can only detect clusters that are linearly separable.
But if we had a dataset that is not linearly separable like the following, the algorithm does not work.

The idea then is to project our data onto an high dimensional kernel space using the kernel trick and perform the k-means algorithm in that new space.
Obviously this increases the computational complexity of the algorithm, because we have to compute and store the result of the kernel function on the samples.
So if in the normal k-Means algorithm we have to minimize the following objective function  now we have to replace the sample x_i with the kernel and so it becomes
now we have to replace the sample x_i with the kernel and so it becomes