all the neurones will have same values in a hidden layer( after single/ all iteration, as derivate will be same). As both the neurones learning same thing, There is no contribution towards gradient but only on scale.
Its like having only one neuron in every layer.
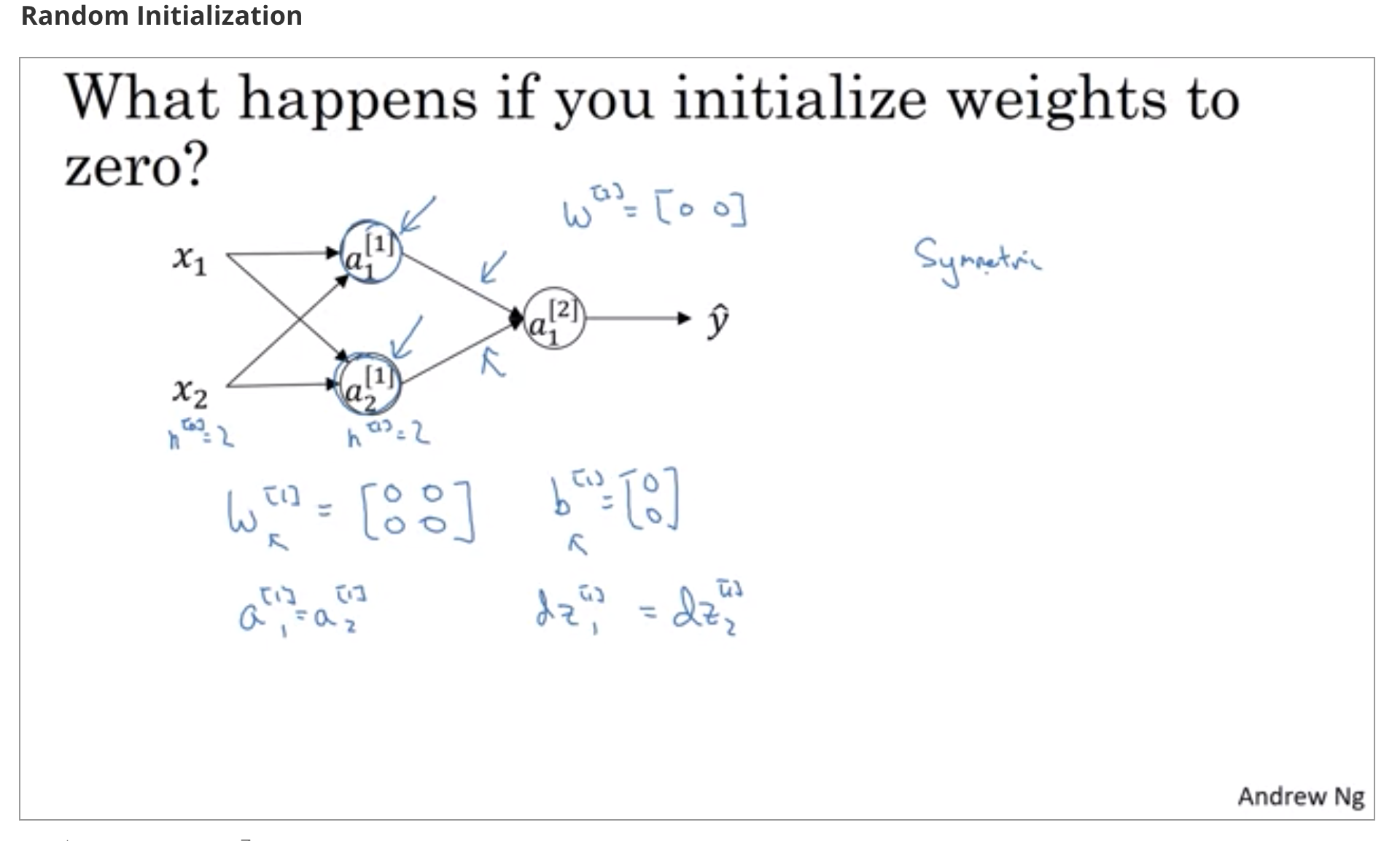
Complete info:
https://datascience.stackexchange.com/questions/26134/initialize-perceptron-weights-with-zero